
Introduction
I honestly can’t remember the last time I met with a prospective client where they didn’t bring up Automation or the term DevOps in the conversation. Both terms have become the popular buzzwords in the IT Industry over the last 5 years. It doesn’t take long for the technologies that are prevalent in this space to come up such as Ansible or Terraform. Everyone understands the basic definition of automation as having the machines do the process of building or modifying objects. But how can this be applied to an organization successfully? Let’s dive into the Automation and DevOps space and see how Azure DevOps can benefit in this endeavor. Let’s unleash our inner DevOps ninja!!!
What is DevOps?
As stated earlier, most people in the IT space are familiar with the term “DevOps”; but what does it really mean? DevOps is often defined as the tools that make up its common solution patterns; but it is not the tools themselves, but the manner of their use. DevOps is an organization’s cultural mindset and methodology which is achieved by collaboration.
Automation Journey
Alright, so now you’re ready to get out there and automate your infrastructure in a week and go full DevOps with Infrastructure as Code and CI/DIC Pipelines, right?! Wrong!! As awesome as automation is, just like with anything, it takes time to implement organizational change. As discussed earlier, DevOps is a culture and a mindset, one of the biggest pitfalls I have seen organizations fall into, is just going all out on automation; without having a broader strategy or standardization. This leads to the creation of “technical debt”; which is defined as the “debt” incurred by IT teams by exploring the more expeditious solution to the problem, without regard to the efforts it will take to maintain the solution in the grand strategy.
An example of technical debt would be this scenario. At a large organization, they acquire another company. Because the deal signed by the business requires the integration to take place within a 30-day period, the infrastructure team forklifts all their OneDrive data, file shares, users, etc. into one big share, not following the standards of the acquiring organization. They plan to sort things into their infrastructure “later on”. The problem with this is all those users must now be treated differently than the standard users, which leads to all their issues going to the team that performed the acquisition.
The point of the story is that we must make operational decisions today that will not adversely affect us in the future. Automation efforts must begin by outlining all the objectives, developing processes and standards, and deploying out incrementally along an automation journey. There are levels and steps along this journey; I recommend starting with Imperative Automation tools to begin with, which you probably even already use these!
Now, let’s get started on our Automation Journey.
Imperative Automation
Our Automation Journey begins at the first stop, Imperative Automation. Imperative automation tools all involve the user defining and mapping out all the steps along the process and the task to be executed. Examples of these would be PowerShell scripts, bash scripts, cli commands, etc. (I mentioned these would be familiar!) These tools are good for one-off tasks but are heavily prone to user error. It can also take a long time to develop scripts in this manner and oftentimes requires specific knowledge about the technology. This means making one for a lot of different tasks individually, which doesn’t scale extremely well. But it’s a start!
Declarative Automation
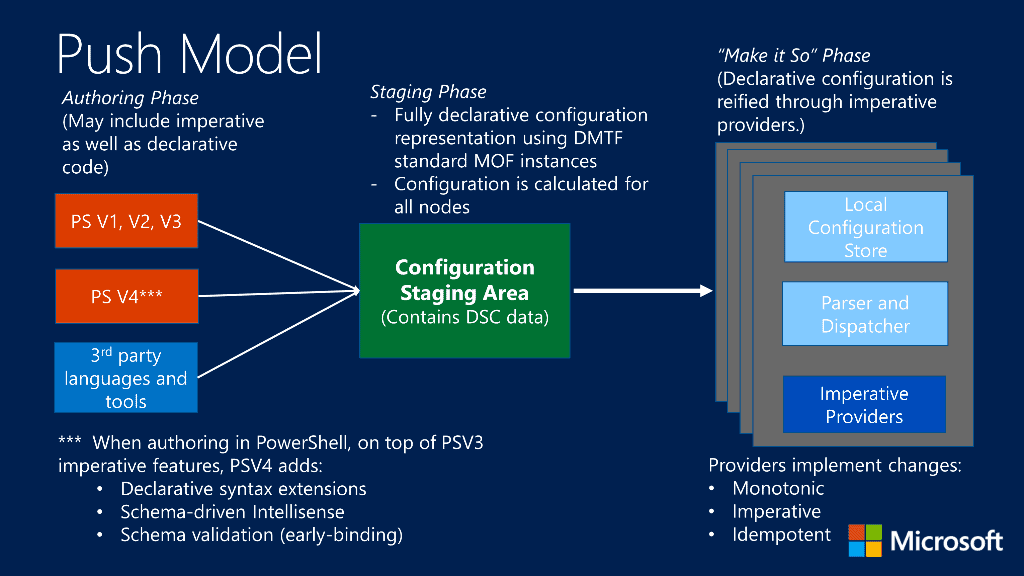
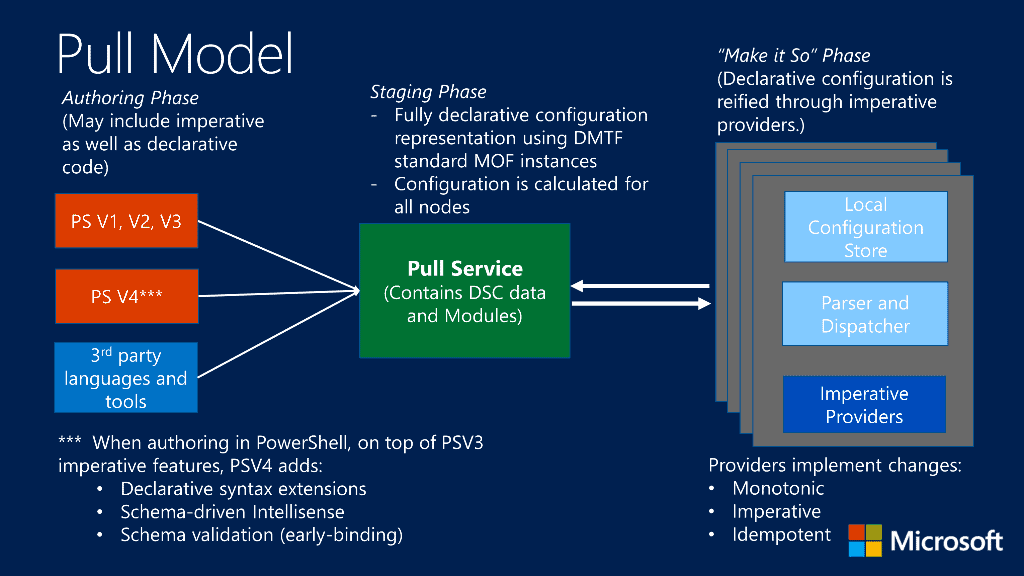
Moving down the line, the next stop along our journey will be Declarative Automation. These tools allow us to describe the infrastructure and objects we want, and the tools themselves will build them. Oftentimes, these tools do not require knowledge of all the steps needed to complete the tasks themselves. Examples of Declarative Automation would be PowerShell Desired State Configuration, F5 Declarative Onboarding, etc. This usually involves a process of “pushing” a configuration from a template that then builds the configuration directly. In the pull model, a base configuration exists, and other sources “pull” from this and makes the configuration of the objects the same as the base configuration files.
An example of the Push Model for PowerShell DSC:
The Pull Model:
Mutable vs Immutable Infrastructure
Most people think of their infrastructure as a static platform they use to run apps or other functions within their environment. This is the classic definition of mutable infrastructure, which means static servers or platforms that are configured to stay in place indefinitely. There are obvious disadvantages to this model. In the event of a disaster event or other such malfunction may happen, it will then require an entire copy of the primary infrastructure in a highly available scenario. This model also lends itself easily to configuration drift, which means servers can fall behind on updates or may have been missed in some sort of manual task.
Immutable infrastructure is the opposite of this. It is dynamic, meaning that the infrastructure exists as code (IAC), and the actual platform can be deployed anywhere that code will execute. This methodology and workflow obfuscate the service layers to the point that only data matters. This can make any organization agile and quite “dangerous” indeed!

Development Practices Lead to Evolution
IAC is the highest level of automation, but what does this mean exactly? Let’s start by looking at where the concept of Infrastructure as code originated. IAC is based on Software Development Methodology, drawing a parallel Infrastructure workflow using coding best practices. The first of which is called the waterfall method and involves progress from one task to the next sequentially.
However, this proved to be inefficient, so a group of practices was created to be more flexible and lightweight, this is called Agile Methodology. These methods place a heavy focus on the product, flexibility, and collaboration within and between teams. An example of this would be Scrum; in this Development Methodology, the primary focus is the team being able to adapt to changes in the project itself and from the client. This process usually involves a daily meeting where the team discusses their current work streams and if they are being blocked on progress and is usually facilitated by a Scrum Master.
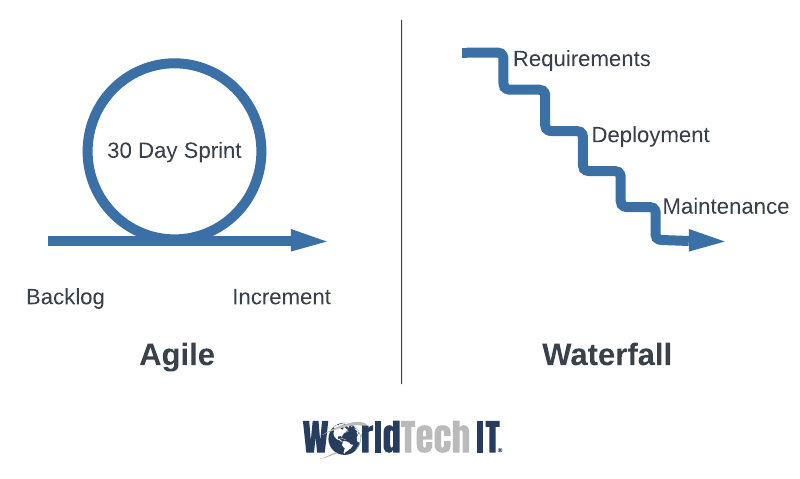
These concepts lead to such success, Infrastructure teams began to put this process in place for deploying infrastructure. This means that all parts of infrastructure such as virtual machines, storage accounts, virtual networks, F5 load-balancers, etc. will exist as objects within a module, within a hierarchy. Inside of an application, we see different blocks of code that correspond to functions and processes that make up how the application works:
Version Control
Let’s pause for a moment along our journey and talk about one of the pillars of IAC and good coding practices in general. Versioning is a process where once code becomes production, it should not be altered directly as this may cause unforeseen issues. So, when we want to make changes we pull a copy of the production down to our machine, give it a version number, make the desired changes, and finally make a pull request to have it checked back in once validated. There are many advantages to this practice as it makes changes easy to roll back and easy to review before implementation. The most common tool for this is Git, which is Open Source. It’s also important to have a safe, shared space where code is stored, this is referred to as a Repository.
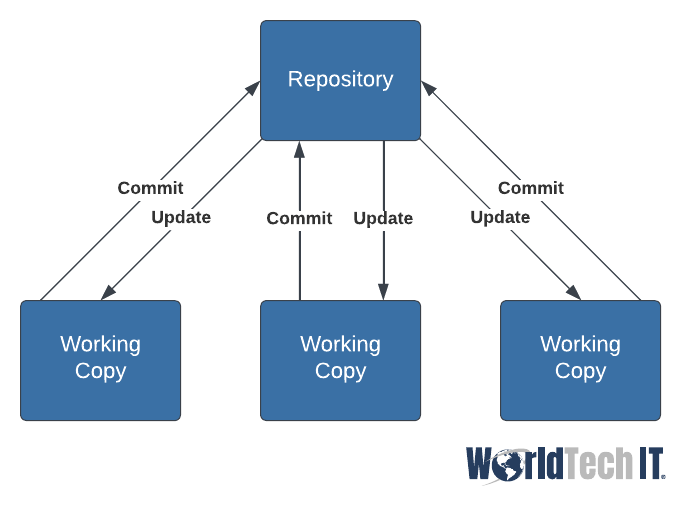
Alright now back to our journey, let’s check out Infrastructure as Code in action using one of the most popular tools!
Infrastructure as Code in Action
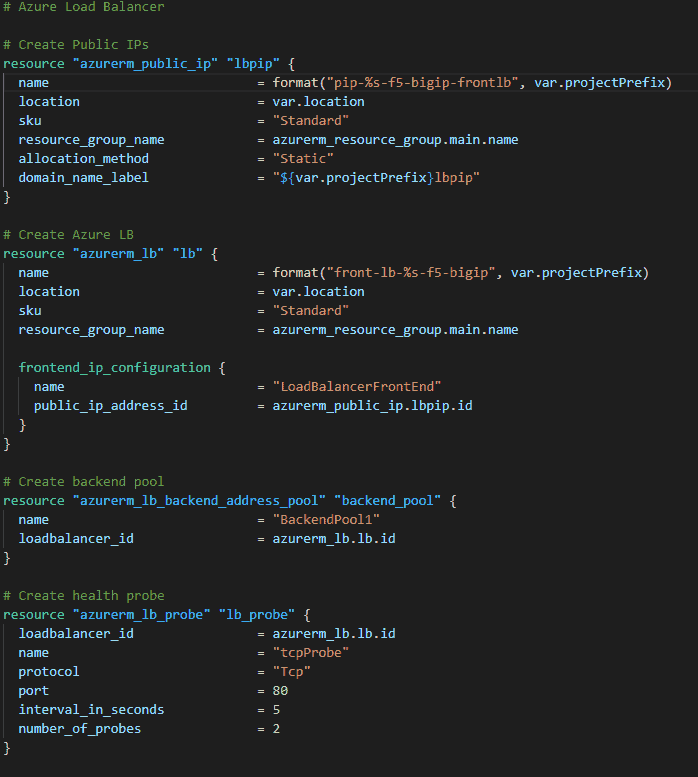
Terraform is a good example of this; in terraform we create .tf files and use HCL (Hashicorp Command Language) to create code that will represent actual objects and services we wish to create. The idea is to create code that is modular, we do not want to create one big file, but break it up between logical segments and smaller chunks. This is important because this code is our infrastructure, so when we modify it, our infrastructure is immutable, so objects may be created or destroyed. We can also create different. tfvars files to represent different environments or some other logical breakdown. Here is an example of how terraform works and some terraform code that builds an Azure Load-Balancer:
5 Principles of Infrastructure as Code
- Systems must be easily rebuilt: It should be possible to rebuild any element of the infrastructure with very little effort
- Systems are Immutable: All resources should be easily created, destroyed, replaced, resized, moved, etc.
- Consistency is Key: all object types should be identical in configuration by function, with changes for Ips, hostnames, etc
- All Processes Should be Idempotent: Any action carried out in the environment should be repeatable and have the exact same results (with the obvious configuration differences)
- Design is Dynamic – A system and the design should be able to be easily and quickly changed
Configuration Drift
Most organizations that deploy servers statically have issues eventually with what is called Configuration Drift. An example of this would be if there was an issue with IIS running on a web server to fix a specific problem, it is not applied to other servers. Another example would be if IIS is manually configured by 3 different people on 3 different servers, in 3 different ways. The issue with these variations is they have not been captured and cannot be applied towards the standardization of the environment. It also involves technical debt, especially if none of the variations are documented. This is known as having a “drift” in the configuration across the environment, which leads to huge amounts of technical debt down the road, as well as a barrier to automation.
Server Lifecycle Management for Configuration Management
The Lifecycle of a Server:

The best solution pattern to manage servers involves eliminating as much variance as possible. We achieve this by first creating a base configuration or template that will be applied to all servers created using the process. The next step is to then create sub-templates based on configuration sets, such as a web server or database server, that include the required configurations for servers in that role. This allows some flexibility, yet still maintains a consistent configuration.
What is a CI/CID Pipeline?
This is another term that’s been thrown around a lot in the last couple of years. But what is it and what does it mean? Let’s get into it…
Continuous Integration
Let’s break it down and start with the CI part and work through it. Continuous Integration is the process of integrating code changes from multiple sources into a single shared repository or project. This practice has become the best practice for software development as it touches on all the pillars of DevOps we discussed earlier, especially collaboration between teams. Working out of one shared location has the benefits of making it way easier to detect and fix bugs, avoiding duplication of effort, reducing systemic risk, and version control. Though it is not required, there is usually automated testing involved in this process as well. An example of this might be a shared Azure Repository in a shared project in Azure DevOps.
Continuous Delivery
The CID or Continuous Delivery portion of our definition involves the entire process from start to finish. This revolves around the principle of being able to make code changes to an application or infrastructure reliably and at any time. (Yes, this means pushing to Production, ideally the more times a day the better!). This is achieved by implementing Continuous Integration, the CID part cannot exist without the CI portion. There are many ways to achieve this, but they mostly revolve around deploying the code changes to a development environment after the build stage has completed, having automated tests that validate the deployment, then having a build artifact that has been validated. Every change is built, tested, and pushed to non-production, before going into the production environment.
Pipeline – Putting it all together
Alright, so now we know what CI/CID practices are, but how does the pipeline come into play? Basically, a pipeline will take advantage of the Shared project or repository used in Continuous Integration. This project or repository is used to deploy the code changes into a new build, deploy the build to non-prod, do automated testing, create the validated build artifact, then proceed onto the production changes. The pipeline comprises the technology portion and all the automated steps that take place during the process. Popular platforms for this are Azure DevOps Pipelines or Ansible Tower Job Workflow templates.
Orchestration – Automating those Automations
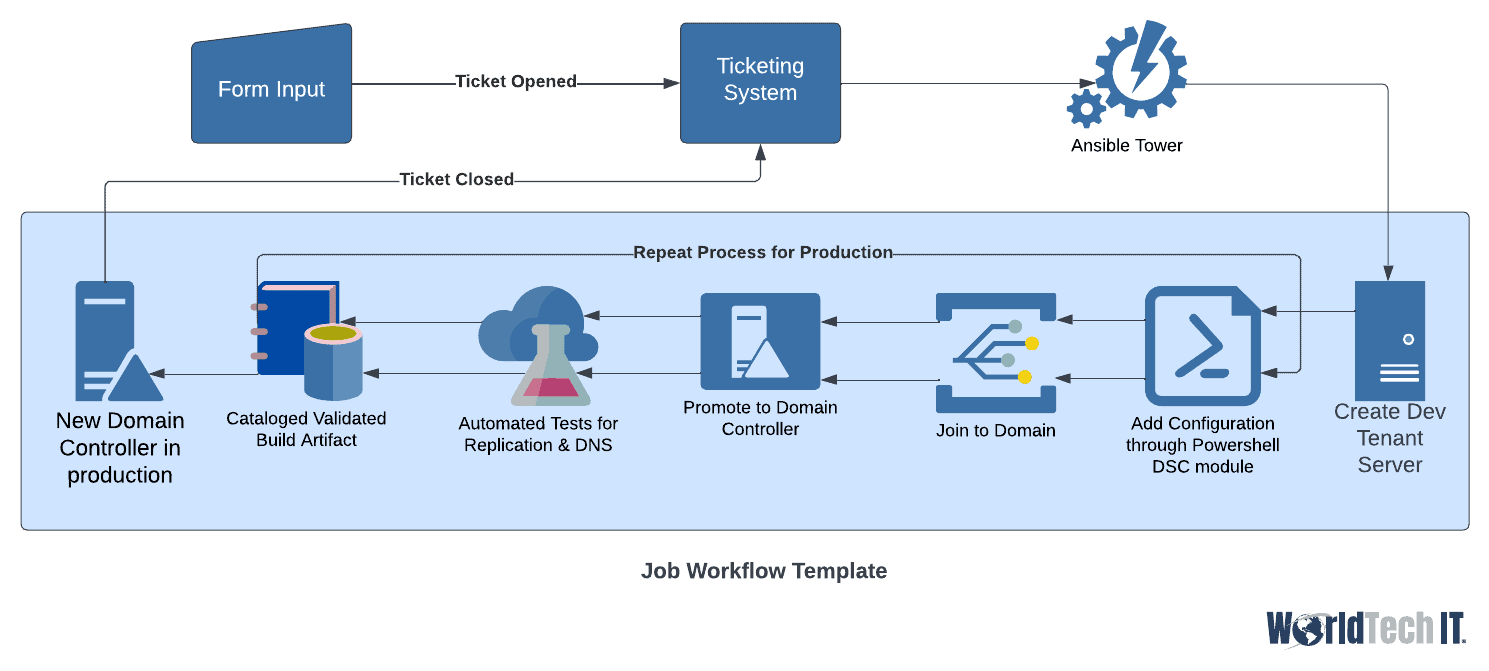
Now that we have automated our processes, created all our Infrastructure as code, and got our CI/CID Pipelines in place, where do we go from here?! The answer is we scale it up even more! How we accomplish it is by creating self-service options for users or clients that run our automation in a logical order to gather a result. We could for instance have our ticketing system include form fields. The form fields could then be pushed to Ansible Tower, which would kick off a job workflow template using these variables. Say this one was to build a new domain controller in Azure. The server would be created in the dev tenant first, then have the configuration added using Powershell DSC module with Ansible, joined to the domain, and promoted to a dc. Once this is created, automated tests begin to verify replication is occurring properly, DNS is resolving from the new dc, and it is advertising properly. This is then cataloged as a validated build artifact and the process begins the same tasks in the production environment. Once the tests validate the Production dc is built and functioning properly, the last step closes the ticket and sends an email to the user containing the name and IP of the new validated domain controller.
Stay tuned for Part 2 coming soon! Follow us for more information on our Microsoft Azure & Microsoft 365 Services!




Leave a Reply